About
This is the proposed mini-thesis for my B.E degree at Yangon Technological University. During the past couple of months, since I was very new to the field of AI, Machine Learning, and Deep Learning, I had to learn in a short amount of time. My field of focus was full-stack web development, therefore, I’m not a professional in this field of AI, so pardon my mistakes if any comes up. In this article, I’m gonna skip signal processing theories for the preprocessing stage just for simplicity. Outlines of this article:
- Speech Synthesis in general
- Possible ways to develop a TTS
- Applied Methodology
- Experimental Results
Here is the IEEE research paper that I’ve coauthored with
Introduction to Speech Synthesis
Text-to-Speech is an joint research area of digital signal processing (DSP) and natural language processing (NLP). In text-to-speech, the goal is to generate a natural-sounding, human-like speech from the input words or sentences in terms of intelligibility and quality which is why for machines, it is a very difficult task. In a technical point of view, speech synthesis can be viewed as a sequence to sequence mapping problem as a sequence of characters are converted into an output audio waveform which is a time-series. Due to this nature, it is possible to achieve this goal by using sequence models.
Approaches
There are two main ways to approach this problem of synthesizing speech. The first one is more of a traditional way used before deep learning. In this type of approach, there are essentially two main stages: Text Analysis and Speech Synthesis. Text analysis is responsible for extracting linguistic features such as phonemes, prosody, etc. The real generation of the audio waveform occurs at the second stage. Similarly, there are also two possible ways to generate speech: either concatenative or parametric. (Refer to the below figure to find out the differences)
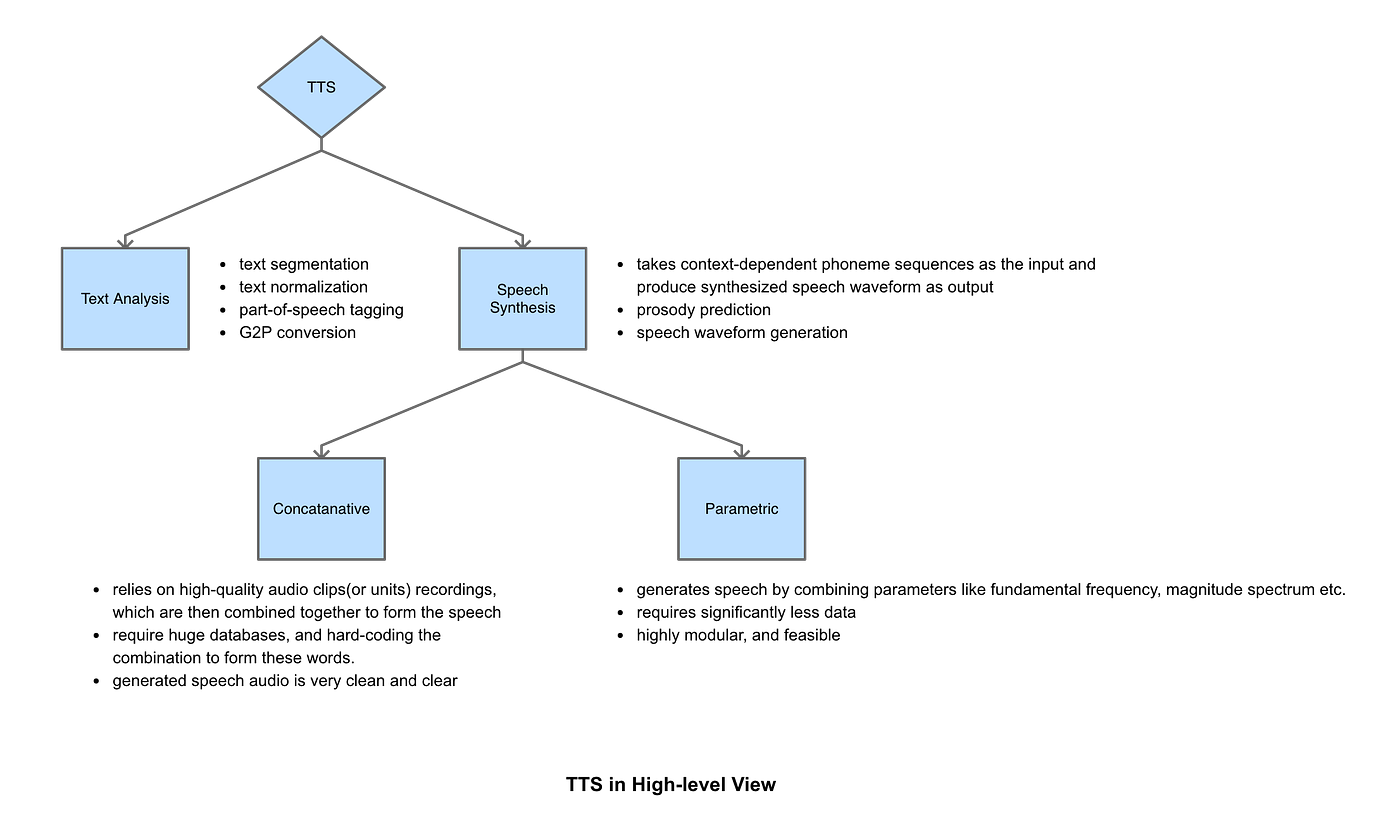
Traditional Speech Synthesis
When I got the thesis title for the first time, I decided to go with this approach as it can generate the best quality audio. I developed a sentence-level G2P (Grapheme to Phoneme) conversion by following Sayar Ye Kyaw Thu’s myG2P dictionary. However, I got stuck at the synthesizer stage as it requires domain expertise in many levels and therefore, I had to change my plan. I’ve always wondered about generating speech directly from the input characters and luckily, there has already research going on.
End-to-End Speech Synthesis
The idea of this approach is to synthesize speech directly from the characters. It does not need phoneme-level alignment and can be trained on completely from scratch given <text, audio> pairs. There are a number of generative models already exist for this purpose, but some of them are not necessarily end-to-end as they usually have models developed and trained separately. Among these models, I decided to go with Tacotron from Google as it is truly an end-to-end generative model that can fulfill our goal.
Tacotron
The backbone of Tacotron is a seq2seq model with attention. Tacotron takes character sequence as inputs and outputs raw spectrograms which are later reconstructed using an algorithm called Griffin-Lim. It operates at frame-level which is why it is faster than sample-level auto-regressive models like WaveNet and SampleRNN. It consists an encoder, an attention-based decoder, and a post-processing net. The encoder is responsible for building up a well-defined summarized representation of the input character sequence. The decoder has to learn about the alignment between the text representations and the output audio frames based on the context.
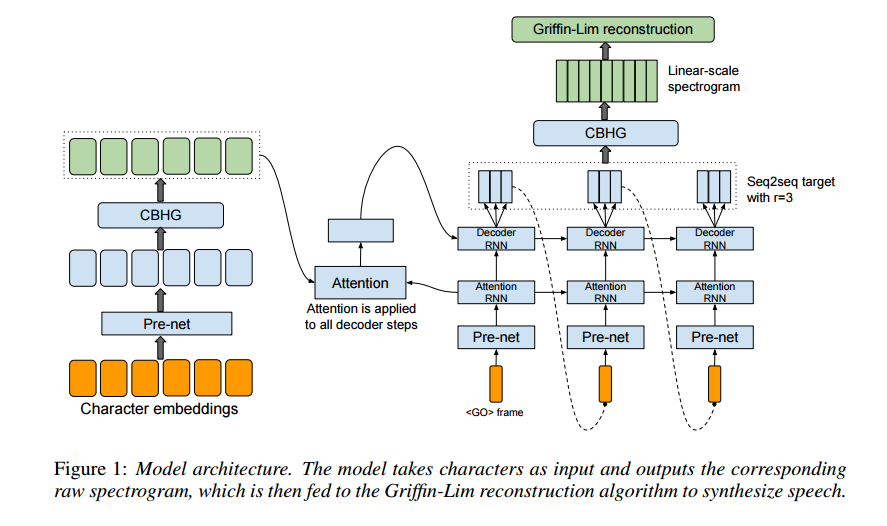
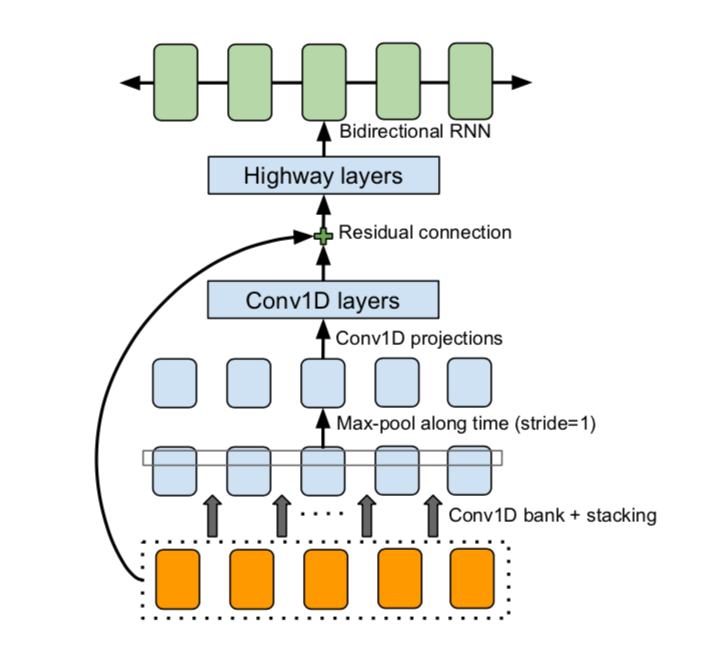
Developing a Burmese Text-to-Speech
Speech Corpus
In order to use Tacotron, we need to have a speech corpus. So, I had to make recordings of me reading Burmese sentences. The text corpus is provided by Base Technology (Expa.AI) and they also allow me to use a web-based recording tool that is able to record and create the mappings of the audio and the text. The final speech corpus contains over 5000 utterances. Totally, this is for about 5 hours. The maximum input text length is 167 and the maximum number of frames in the input audio is 907.
Model Implementation
Google did not release the official implementation of Tacotron but there are some great implementations on GitHub. I referenced from this repository and added some other necessary modules. I had to develop a module for converting from numbers to words as the corpus contains numbers in texts. This module is also available here in this repo.
Training
I trained this model for 150,000 steps which took me about a week. Since I used Google Colab for training, I only have access for 12 hours. I had to restart from mounting my google drive to preprocessing and training every single time :(.